AWS Serverless FTP File Processing Service 👊
Learn how to create a Serverless, highly available data processing system with strong durability and elasticity using AWS 🧡.

Introduction
In this article, we aim to tackle a common business task which is file processing 📂. If you’ve been in development for some time, it’s quite probable you’ve needed to grab a file from a resource (such as FTP server) perform a read/write operation, and store the results in some form of managed data structure such as a DBMS.
From batch scripts to Windows Services 💻, there’s dozens of ways to accomplish this, let’s see how we can use a modern approach using AWS resources.
The Scenario
Acme Corporation 💥 need a file processing system, this needs to pick up CSV files from an FTP server and read the data, each file requires an external API check on some fields. It’s been known for the CSV files to have issues in the past regarding their formatting, the system should flag files it cannot process for manual inspection. The system should continue to process other files regardless of individual file issues.
During the Christmas period 🎄 the company have an influx of files, being able to process more files than the average whilst maintaining the same time period is important.
Polling & Transfer Service
Let’s briefly go over the process flows available in this diagram as a ‘best effort’ goal of defining their purpose.
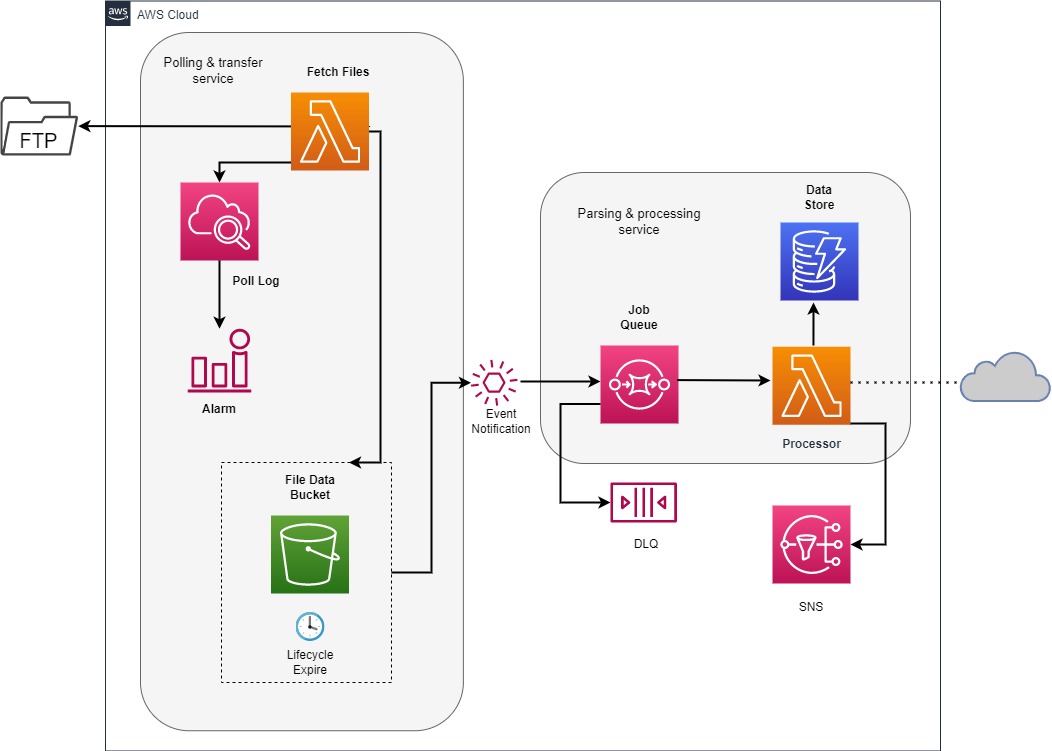
1. Lambda (File Fetch)
![]()
This is our poll service, its sole purpose is to connect to the FTP server on an interval, check a directory for files, download and send them to an S3 bucket.
✅ File Processing - There’s no processing of this file in here, the reason is our Lambda can only concurrently run for 15 minutes, we don’t want our Lambda stuck processing and downloading each file.
✅ Security - The above gives greater separation of concerns, which in turn enables us to have a refined execution policy with specific resource access.
2. CloudWatch
![]()
As the Lambda is used file polling and downloading, the CloudWatch log data becomes more granular via just logging those I/O events. We can create some alarms which will alert users to issues via SNS or direct e-mail depending upon requirements.
There’s isn’t much to discuss, other than this is highly useful for event tracking and debugging.
2. S3 (File Bucket)
![]()
This acts as our temporary document store for our downloaded files and is a key part of our distributed, resilient file processing service. We will transfer our data over a VPC Endpoint to our Bucket, ensuring this doesn’t travel over the public Internet. There’s a good few advantages to storing the documents in our service, lets first go over features of S3 we’re leveraging.
✅ Lifecycle Policy - We’ll use this to delete our files automatically to save cost. The retention may need to be agreed upon by the data provider or your company to consider PII when retaining the file. If there’s a processing issue we don’t need to re-download from the remote server.
This can be incredibly useful not only for saving time and operational overhead, but files can be short-lived or overwritten on FTP servers and therefore we avoid the headache of asking for files.
✅ Event Notification - We can hook into new object created events, allowing automatic integration with AWS SQS, queueing our file for future processing without writing any code.
Parsing & Processing Service
3. SQS
![]()
Our SQS allows for massive flexibility and resiliency and provides a mechanism for decoupling between our service architecture. Let’s outline some of the benefits here:
✅ Automatic Retry - If the Lambda fails to process a file, the entry in the queue will re-appear due to visibility timeout mechanism, processing files involves hitting an external API for validation which could experience issue, in this case n retries is great to cope with random failure outside of the services control.
✅ DLQ - A dead-letter queue is incredibly useful for our scenario, we want to know if a file cannot be processed and most importantly we need to know which file in question needs to be inspected, it could be our code, or simply an issue with file. Furthermore, since our message is moved to the DLQ, it stops a finite amount of processing attempts, saving time, money, and potentially blocking other files from being processed 👍.
✅ Elasticity - Currently one Lambda to process files is enough, however, if the velocity of files grows, using event source scaling, horizontally scaling n amount of Lambdas based upon our queue length 👌.
4. Lambda
![]()
Here’s our file processor, it’s job is to read files, perform some data transformation and call a third-party service to validate attributes, once this has been completed the data is then stored in a DynamoDB table for other services outside of the scope of this problem to consume.
- For this, we can use the S3 VPC Gateway endpoint to keep the file stream off the public Internet and purely in the AWS private network, eliminating S3 data transfer cost too.
- We could use batching to save invocation cost via batching our SQS messages together, however, this would make debugging a file failure more troublesome and isn’t needed for our requirements
- We can give our Lambda explicit
iamRoleto access our specific DynamoDb table via its resource id, this allows us to easily follow least privileged and simply grant what we need - We can put a Lambda in our VPC and therefore restrict via Security Group to access required external services
5. SNS
![]()
The SNS sends a notification after processing, this could send an e-mail or log a successful process and if there’s a consistent baseline, have an alarm trigger below that threshold for a manual review.
Worthy Mentions
Since we don’t want to get too tied down with all the options available in regards to resource configuration, I’ve omitted what we don’t need to save the article from being exhaustive, here are a few things to consider for similar scenarios
👉 FIFQ Queue - This guarantees order and prevents possible duplication of messages in a SQS, highly useful if duplication of messages cannot happen or order of messages is crucial
👉 S3 Cross Region - If this was a mission-critical system or our files could never be re-created, exploring S3 region replication would be useful as part of a disaster recovery plan
👉 Batch processing/size - Increasing the amount of messages included in a single Lambda invocation, this could make debugging an individual files more difficult, but would result in a performance increase (due to lack of warmup time) and some cost saving from a time POV
👉 AWS Transfer Family - A little outside of scope, but if the FTP server created using AWS Transfer Family, not only would this resource scale automatically, it would also provide workflows to transfer directly to S3 or EFS. In our scenario this would save work and reduce complexity.
Conclusion
That’s a wrap for the service, this scenario should be an approximation of a standard file processing systems and default presumptuous expectation; i.e. it should fail to work if a single file cannot be processed, the culprit should be logged etc. We’ve skipped much of the finer detail to avoid verbiage.
Ash Grennan
Snr Software Engineer
Deliver value first, empower teams to make technical decisions. Snr Engineer @ Moonpig, hold a BSc & MSc in software engineering & certified AWS Solutions Architect (LinkedIn). A fan of Serverless computing, distributed systems, and anything published by serverless.com 🧡